Speed comparison on the c64: BASIC, C, assembly
Having recently gotten back into programming my Commodore 64, I discovered the cc65 project. Searching for example code, I came across this page since it included an example of updating the color matrix ($d800). After running the samples there, I became curious about code speed using various tools.
In addition to the color matrix, I was also interested in the screen matrix, so I rewrote it to update the screen text using something like this:
void main()
{
int i;
char *mem=(char*)0x0400;
for (i=0; i<1000; ++i)
++mem[i];
}This was a nice first attempt. It produced a rather assembly-like feel compared to the slowness of BASIC, and the resulting program was less than two blocks. In order to improve readability, I decided to run the routine 256 times. That way it would return the screen to a readable state.
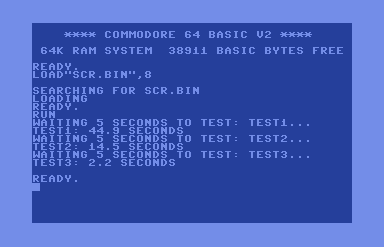
I quickly discovered that, although this seemed fast at first, it was still very far from optimized assembly. So I produced 3 versions of the program and wrapped it into a benchmark of sorts. I also wrote BASIC versions in order to fully understand the speed issues. Here is the cc65 compiled program output which tests 3 versions: the straightforward code above, an optimized version (below), and a version using inline assembly. You can't see the screen flickering here, but it's quite a show. Here is the final output:
I actually wrote the assembly version second, and came up with the following:
LDX #231
l1: INC $0400,x
INC $0500,x
INC $0600,x
INC $0700,x
DEX
BNE l1
INC $0400
INC $0500
INC $0600
INC $0700
LDX #232
l2: INC $0400,x
INC $0500,x
INC $0600,x
INX
BNE l2Finally, adapting some of the tricks in the assembly version, I wrote the new C version below. It reduces the time from 44.9 seconds to 14.5 for 256 iterations. Most of the gains come from using a byte for indexing.
void test2()
{
byte i;
char *m0, *m1, *m2, *m3;
m0=(char*)0x0400;
m1=(char*)0x0500;
m2=(char*)0x0600;
m3=(char*)0x0700;
i=231; do {
++m0[i]; ++m1[i]; ++m2[i]; ++m3[i];
} while(--i);
i=232; do {
++m0[i]; ++m1[i]; ++m2[i];
} while(i++);
++m3[0];
}Here is a table of speeds for 256 iterations running on an NTSC machine. As you can see, although I was able to improve heavily on my first attempt, C version 1 still trounces the BASIC compilers by an order of magnitude while also producing much smaller code.
| tool | runtime |
|---|---|
| C version 1 | 44.9 seconds |
| C version 2 | 14.5 seconds |
| inline assembly | 2.2 seconds |
| BASIC version 1 | 2875 seconds |
| BASIC version 2* | 2097 seconds |
| BLITZ! Compiler** | 508 seconds |
| SpeedCompiler 2.2** | 640 seconds |
* BASIC version 2 replaces heavily used constants with variables
** Both BASIC compilers were fastest with BASIC version 1
The BASIC code is interesting. Originally I did only 128 iterations because it had the amusing effect of inverting the entire screen at the time of the run. My original code was a fair bit faster (even doubling to get 256 iterations) because it didn't guard against poking a value greater than 255. I didn't notice the bug because nothing on screen was over ASCII 127 at the time of the run! I only discovered it while trying to produce runtimes for 256 iterations. No, I did not sit there for 1.5 hours running the BASIC tests-- thankfully VICE has warp mode. The crucial line:
poke i,peek(i)+1had to be replaced with:
poke i,(peek(i)+1)and 255resulting in half the speed!
Here are the project files which include scvtest.c for the VIC20.